The Gothenburg model and CollateX
Outline
- The Gothenburg model
- History
- Goals
- Components
- CollateX
- What it is CollateX?
- Collation pipeline in CollateX
The Gothenburg model: history
- Developers of CollateX and Juxta
- Joint workshop: Gothenburg 2009
- Sponsored by COST Action 32 and Interedition
Goals
Identification of the core components of textual comparison at an abstract level
- common understanding
- facilitation of collaboration
Components
- Tokenization
- Normalization/regularization
- Alignmemt
- Analysis
- Visualization/output
Prerequisite: an electronic text version of each witness
1. Tokenization
- Division of the continuous text into units to be aligned (tokens)
Would you care for a sherbet lemon?
--> Would | you | care | for | a | sherbet | lemon | ?
1. Tokenization
- Division of the continuous text into units to be aligned (tokens)
- Any level of granularity
- Typically: whitespace-delimited words
- Other options: syllables, lines, phrases, verses, paragraphs, text nodes...
Tokenization: challenges
- Ambiguity
- Punctuation
- Language specific issues: contractions, superscription, etc.
- Markup
Tokenization challenges: some examples
- He remarked, “John said, ‘Bout starts at nine.’”
- He remarked, “John said, ‘It’s ’bout time.’”
- Tu es un %#@$!
- Oh d--n it!
- MASS.
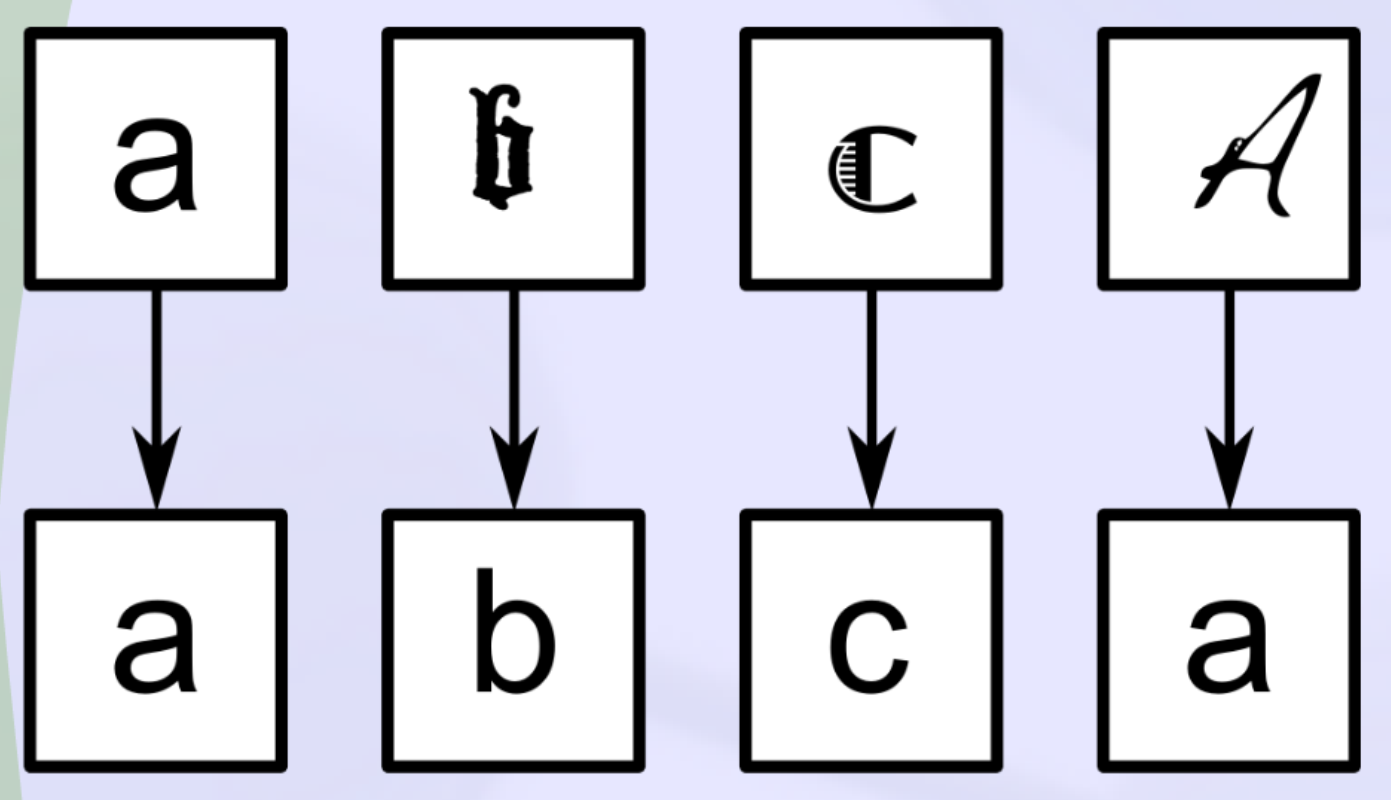
2. Normalization/regularization
- Normalization during transcription vs. collation
- Ignore non-substantive variation for comparison
- Punctuation
- Upper/lower case
- Orthographic variation
- Allographs (letterforms)
- Abbreviations
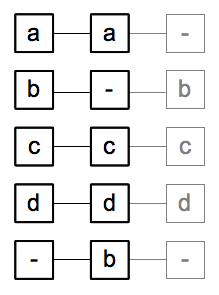
3. Alignment
- Find the tokens that match
- Introduce gap tokens when necessary (“omissions”)
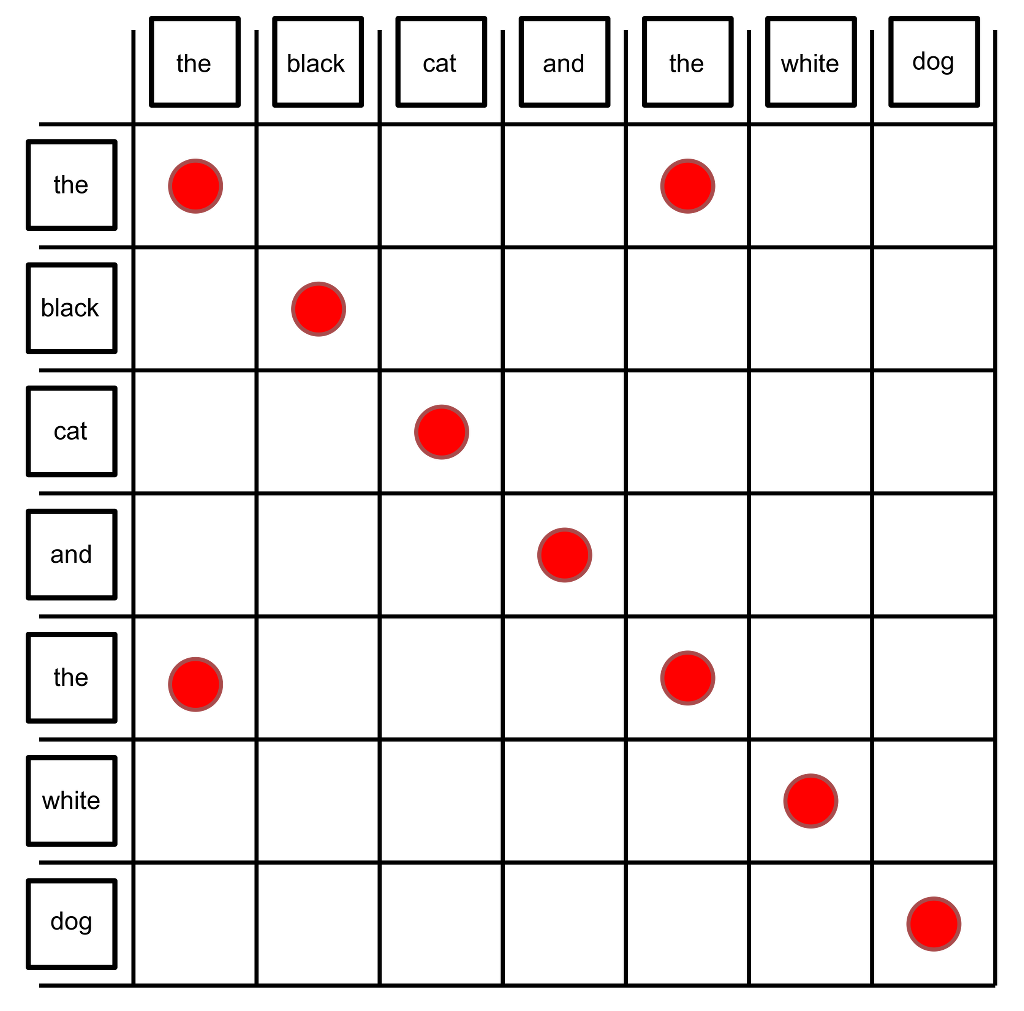
Alignment of tree witnesses
Alignment: challenges
- Computational complexity
Alignment: challenges
- Repetition
- Transposition
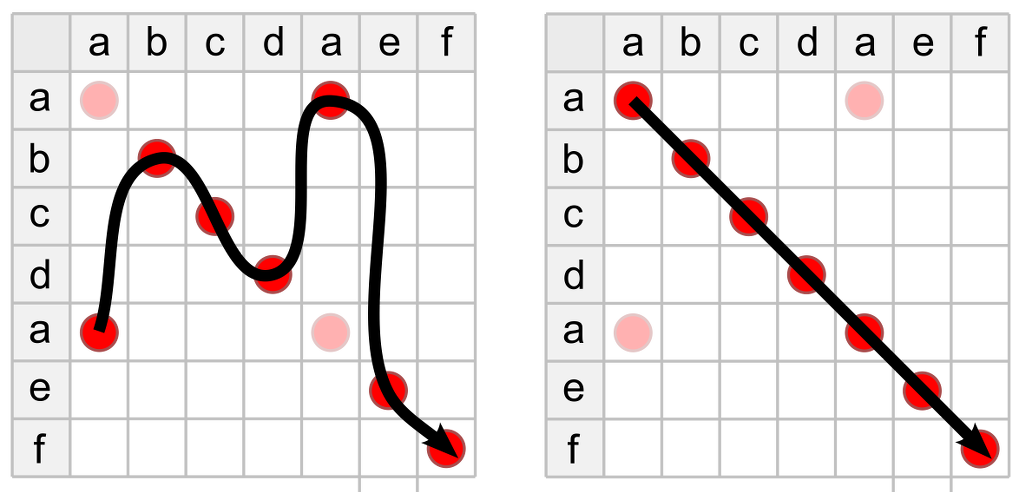
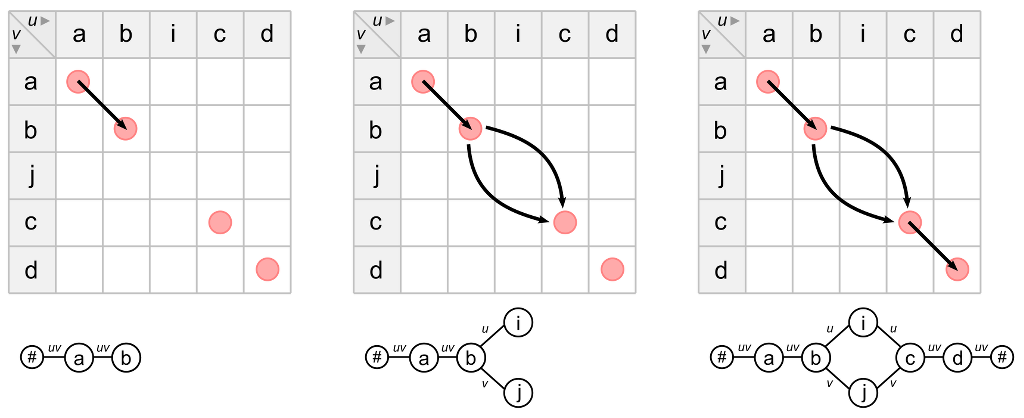
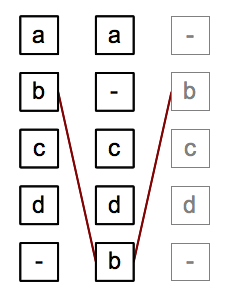
Alignment: challenges
- Order effects
4. Analysis/feedback
- Intepretation beyond linear alignment
- Manual intervention?
→
5. Visualization/output
- Markup for further processing
- XML, TEI, JSON, GraphViz DOT, LaTeX, etc.
- Textual visualization, for examination and analysis
- Textual alignment table
- Plain text, HTML, PDF
- Toolkits with additional functionalities: Juxta †
- Textual alignment table
- Graphic visualization, for examination and analysis
- Variant graph
Example
- W1: Introduction à la collation automatique
- W2: Cours sur la collation automatique
- W3: En savoir plus sur la collation automatique
Alignment table
| W1 | Introduction à | la collation automatique | |
|---|---|---|---|
| W2 | Cours | sur | la collation automatique |
| W3 | En savoir plus | sur | la collation automatique |
Variant graph

Collation and/or visualization tools
CollateX
- What it is CollateX?
- Collation pipeline in CollateX
Flavors
- Java
- Web app
- Python
Advantages of CollateX
- Data formats
- Input: Anything and everything (JSON)
- Output: Anything and everything (JSON)
- Control over each step of the pipeline
Collation pipeline in CollateX
- Default behaviours
- Parameters
Tokenization in CollateX
- It divides the text into tokens using whitespaces as delimiter
- Punctuation is tokenized separately from alphanumeric characters
Example: Peter's cat.
| Peter | ' | s | cat | . |
Normalization in CollateX
By default, it removes trailing white space at the end of tokens.
Pretokenized and normalized input
JSON file as input: Each token may present a normalized version
CollateX alignment parameters
- Different alignment algorithms
- Dekker (Dekker & Middle 2011)
- Needleman-Wunsch (Needleman & Wunsch 1970)
- MEDITE (Bourdaillet & Ganascia 2007)
Progressive alignment
- start by comparing two versions,
- transform the result into a variant graph, then
- compare another version against that graph, and
- merge the result of that comparison into the graph;
- repeate the procedure until all versions have been merged.
Analysis in CollateX
Exact vs. near (fuzzy) matching
- A: And Ron pulled out a fat grey rat
- B: And Ronald pulled out a gray rat
Exact matching
| A | And | Ron | pulled | out | a | fat | grey | rat |
| B | And | Ronald | pulled | out | a | gray | - | rat |
Near matching
| A | And | Ron | pulled | out | a | fat | grey | rat |
| B | And | Ronald | pulled | out | a | - | gray | rat |
CollateX outputs
- Alignment table: ASCII, CSV, TSV, HTML,XML, XML-TEI, JSON
- Variant graph: SVG
Alignment table
| W1 | Introduction à | la collation automatique | |
|---|---|---|---|
| W2 | Cours | sur | la collation automatique |
| W3 | En savoir plus | sur | la collation automatique |
Variant graph
TEI
<cx:apparatus xmlns:cx="http://interedition.eu/collatex/ns/1.0"
xmlns="http://www.tei-c.org/ns/1.0">
<app>
<rdg wit="W1">Introduction à</rdg>
<rdg wit="W2">Cours</rdg>
<rdg wit="W3">En savoir plus</rdg></app>
<app><rdg wit="W1"/><rdg wit="W2 W3">sur</rdg></app>
la collation automatique</cx:apparatus>
Bibliography
- Bourdaillet J. & Ganascia J.-G. (2007): “Practical block sequence alignment with moves.” LATA 2007 - International Conference on Language and Automata Theory and Applications, 3/2007.
- Dekker, R. H. & Middell, G. (2011): “Computer-Supported Collation with CollateX: Managing Textual Variance in an Environment with Varying Requirements.” Supporting Digital Humanities 2011. University of Copenhagen, Denmark. 17-18 November 2011.
- Interedition Development Group (2010-): CollateX - Sofware for Collating Textual Sources. https://collatex.net/
- Hoover, David L. (2015): “The Trials of Tokenization.” DH2015, University of Western Sydney, Australia, June 29–July 3, 2015.
- Needleman, Saul B. & Wunsch, Christian D. (1970): A general method applicable to the search for similarities in the amino acid sequence of two proteins. Journal of Molecular Biology 48 (3), 443–53.